概述
DrissionPage是一个基于python的网页自动化工具
它既能控制浏览器,也能收发数据包,还能把两者合二为一
可兼顾浏览器自动化的便利性和requests的高效率
它功能强大,内置无数人性化设计和便捷功能
语法真的简单而优雅,代码量少,对于我这样的新手来说很友好!
安装 1 2 3 4 5 6 pip install DrissionPage -i https://pypi.tuna.tsinghua.edu.cn/simple pip install DrissionPage -i https://pypi.douban.com/simple pip install DrissionPage --upgrade
导入 页面类 ChromiumPage 如果只要控制浏览器,导入ChromiumPage
1 from DrissionPage import ChromiumPage
SessionPage 如果只要收发数据包,导入SessionPage
1 from DrissionPage import SessionPage
WebPage WebPage是功能最全面的页面类,既可控制浏览器,也可收发数据包
1 from DrissionPage import WebPage
配置工具 ChromiumOptions ChromiumOptions类用于设置浏览器启动参数
1 from DrissionPage import ChromiumOptions
设置浏览器的路径 1 2 3 4 from DrissionPage import ChromiumOptionspath = r'xxx\xxx\xxx\chrome.exe' ChromiumOptions().set_browser_path(path).save()
SessionOptions SessionOptions类用于设置Session对象启动参数
1 from DrissionPage import SessionOptions
Settings Settings用于设置全局运行配置,如找不到元素时是否抛出异常
1 from DrissionPage.common import Settings
其它工具 keys 键盘按键类,用于键入 ctrl、alt 等按键
1 from DrissionPage.common import Keys
Actions 动作链,用于执行一系列动作
1 from DrissionPage.common import Actions
By 与 selenium 一致的By类,便于项目迁移
1 from DrissionPage.common import By
其它工具 wait_until:可等待传入的方法结果为真
1 2 3 from DrissionPage.common import wait_untilfrom DrissionPage.common import make_session_elefrom DrissionPage.common import configs_to_here
异常 异常放在DrissionPage.errors路径
1 from DrissionPage.errors import ElementNotFoundError
衍生对象类型 Tab、Element 等对象是由 Page 对象生成,开发过程中需要类型判断时需要导入这些类型
1 2 3 4 5 6 7 from DrissionPage.items import SessionElementfrom DrissionPage.items import ChromiumElementfrom DrissionPage.items import ShadowRootfrom DrissionPage.items import NoneElementfrom DrissionPage.items import ChromiumTabfrom DrissionPage.items import WebPageTabfrom DrissionPage.items import ChromiumFrame
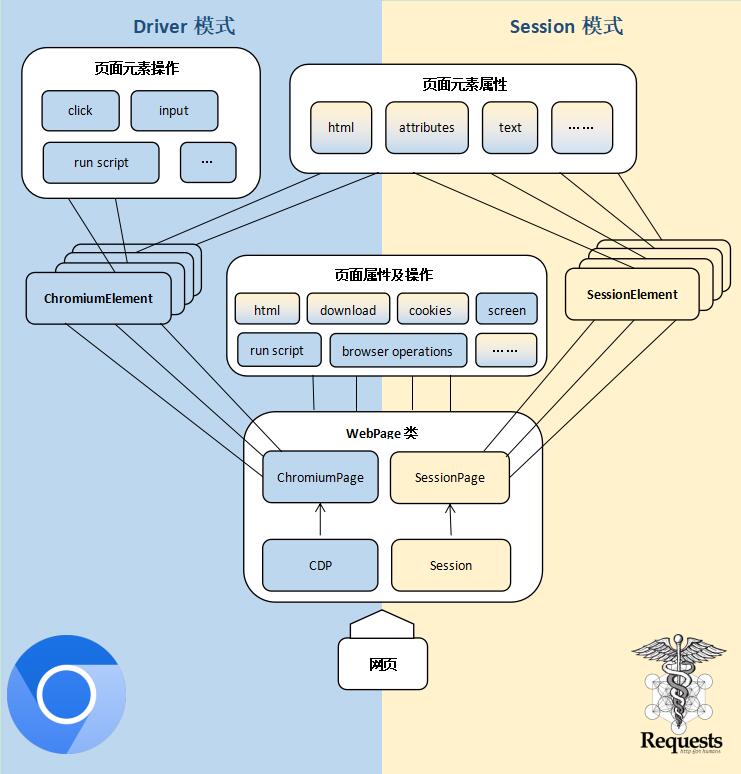
三种页面对象 SessionPage SessionPage对象和WebPage对象的 s 模式,可用收发数据包的形式访问网页。
SessionPage是一个使用使用Session(requests 库)对象的页面,它使用 POM 模式封装了网络连接和 html 解析功能,使收发数据包也可以像操作页面一样便利。
ChromiumPage ChromiumPage对象和WebPage对象的 d 模式,可操控浏览器。
顾名思义,ChromiumPage是 Chromium 内核浏览器的页面,它用 POM 方式封装了操控网页所需的属性和方法。
使用它,我们可与网页进行交互,如调整窗口大小、滚动页面、操作弹出框等等。
通过从中获取的元素对象,我们还可以跟页面中的元素进行交互,如输入文字、点击按钮、选择下拉菜单等等。
甚至,我们可以在页面或元素上运行 JavaScript 代码、修改元素属性、增删元素等。
可以说,操控浏览器的绝大部分操作,都可以由ChromiumPage及其衍生的对象完成,而它们的功能,还在不断增加。
除了与页面和元素的交互,ChromiumPage还扮演着浏览器控制器的角色,可以说,一个ChromiumPage对象,就是一个浏览器。
它可以对标签页进行管理,可以对下载任务进行控制。可以为每个标签页生成独立的页面对象(ChromiumTab),以实现多标签页同时操作,而无需切入切出。
WebPage WebPage对象整合了SessionPage和ChromiumPage,实现了两者之间的互通。
它既可以操控浏览器,也可以收发数据包,并且会在两者之间同步登录信息。
它有 d 和 s 两种模式,分别对应操控浏览器和收发数据包。
WebPage可灵活的在两种模式间切换,从而实现一些有趣的用法。
比如,网站登录代码非常复杂,用数据包实现过于烧脑,我们可以用浏览器处理登录,再通过切换模式用收发数据包的方式去采集数据。
两种模式的使用逻辑是一致的,跟ChromiumPage没有区别,易于上手。
DrissionPage事件 元素定位查找 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 page.ele('@id:ele_id' , timeout=2 ) page.eles('@class' ) page.eles('@class:class_name' ) page.eles('@class=class_name' ) page.ele('#ele_id' ) page.ele('#:ele_id' ) page.ele('.ele_class' ) page.ele('.:ele_class' ) page.ele('tag:li' ) page.eles('tag:li' ) page.ele('tag:div@class=div_class' ) page.ele('tag:div@class:ele_class' ) page.ele('tag:div@class=ele_class' ) page.ele('tag:div@text():search_text' ) page.ele('tag:div@text()=search_text' ) page.ele('search text' ) page.eles('text:search text' ) page.eles('text=search text' ) page.eles('xpath://div[@class="ele_class"]' ) page.eles('css:div.ele_class' ) loc1 = By.ID, 'ele_id' loc2 = By.XPATH, '//div[@class="ele_class"]' page.ele(loc1) page.ele(loc2) element = page.ele('@id:ele_id' ) element.ele('@class:class_name' ) element.eles('tag:li' ) element.parent element.next element.prev ele1 = element.shadow_root.ele('tag:div' ) page.ele('@id:ele_id' ).ele('tag:div' ).next .ele('some text' ).eles('tag:a' ) eles = page('@id:ele_id' )('tag:div' ).next ('some text' ).eles('tag:a' ) ele2 = ele1('tag:li' ).next ('some text' )
元素操作 1 2 3 4 5 6 7 8 9 10 11 12 element.click(by_js) element.input (value) element.run_script(js) element.submit() element.clear() element.screenshot(path, filename) element.select(text) element.set_attr(attr, value) element.remove_attr(attr) element.drag(x, y, speed, shake) element.drag_to(ele_or_loc, speed, shake) element.hover()
获取元素属性 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 element.html element.inner_html element.tag element.text element.comments element.link element.texts() element.attrs element.attr(attr) element.css_path element.xpath element.parent element.next element.prev element.parents(num) element.nexts(num, mode) element.prevs(num, mode) element.ele(loc_or_str, timeout) element.eles(loc_or_str, timeout)
示例 语法较简单,简单看了下语法,弄了几个示例上手一下
多线程操作标签页 此示例演示如何使用多个线程同时控制一个浏览器的多个标签页进行采集 目标网址:
https://gitee.com/explore/ai
https://gitee.com/explore/machine-learning
按F12,可以看到每个标题元素的class属性均为title project-namespace-path,可批量获取
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 from threading import Threadfrom DrissionPage import ChromiumPagefrom DataRecorder import Recorderdef collect (tab, recorder, title ): """用于采集的方法 :param tab: ChromiumTab 对象 :param recorder: Recorder 记录器对象 :param title: 类别标题 :return: None """ num = 1 while True : for i in tab.eles('.title project-namespace-path' ): recorder.add_data((title, i.text, num)) btn = tab('@rel=next' , timeout=2 ) if btn: btn.click(by_js=True ) tab.wait.load_start() num += 1 else : break def main (): page = ChromiumPage() page.get('https://gitee.com/explore/ai' ) tab1 = page.get_tab() tab2 = page.new_tab('https://gitee.com/explore/machine-learning' ) tab2 = page.get_tab(tab2) recorder = Recorder('data.csv' ) Thread(target=collect, args=(tab1, recorder, 'ai' )).start() Thread(target=collect, args=(tab2, recorder, '机器学习' )).start() if __name__ == '__main__' : main()
多线程操作多个浏览器 此示例演示如何使用多个线程同时控制多个浏览器进行采集 目标网址:
https://gitee.com/explore/ai
https://gitee.com/explore/machine-learning
按F12,可以看到每个标题元素的class属性均为title project-namespace-path,可批量获取虽然 gitee 开源项目列表可以用 s 模式采集,但现在为了演示多标签页操作,还是使用浏览器进行操作使用ChromiumOptions的auto_port()方法,可设置独立的浏览器环境,每个浏览器需一个ChromiumOptions对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 from threading import Threadfrom DrissionPage import ChromiumPage, ChromiumOptionsfrom DataRecorder import Recorderdef collect (page, recorder, title ): """用于采集的方法 :param page: ChromiumTab 对象 :param recorder: Recorder 记录器对象 :param title: 类别标题 :return: None """ num = 1 while True : for i in page.eles('.title project-namespace-path' ): recorder.add_data((title, i.text, num)) btn = page('@rel=next' , timeout=2 ) if btn: btn.click(by_js=True ) page.wait.load_start() num += 1 else : break def main (): co1 = ChromiumOptions().auto_port() co2 = ChromiumOptions().auto_port() page1 = ChromiumPage(co1) page2 = ChromiumPage(co2) page1.get('https://gitee.com/explore/ai' ) page2.get('https://gitee.com/explore/machine-learning' ) recorder = Recorder('data.csv' ) Thread(target=collect, args=(page1, recorder, 'ai' )).start() Thread(target=collect, args=(page2, recorder, '机器学习' )).start() if __name__ == '__main__' : main()
下载功能示例 这个示例用于演示下载功能将用两种方法下载最新版 QQ 客户端 使用浏览器下载
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from DrissionPage import ChromiumPagepage = ChromiumPage() page.get('https://im.qq.com/pcqq/index.shtml' ) ele = page('全新体验版下载' ) ele.wait.has_rect() mission = ele.click.to_download(save_path='tmp' , rename='QQ.exe' ) mission.wait()
使用download()方法下载
1 2 3 4 5 6 from DrissionPage import SessionPagepage = SessionPage() url = 'https://dldir1.qq.com/qqfile/qq/QQNT/4a642cfb/QQ9.9.7.21357_x64.exe' page.download(url, goal_path='tmp' , rename='QQ.exe' )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from DrissionPage import ChromiumPagepage = ChromiumPage() page.get('https://im.qq.com/pcqq/index.shtml' ) ele = page('全新体验版下载' ) ele.wait.has_rect() page.set .download_path('.' ) ele.click() mission = page.wait.download_begin(cancel_it=True ) page.download(mission.url, goal_path='tmp' , rename='QQ.exe' )
自动登录gitee 此示例演示使用控制浏览器的方式自动登录 gitee 网站 目标网址:https://gitee.com/login
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from DrissionPage import ChromiumPagepage = ChromiumPage() page.get('https://gitee.com/login' ) page.ele('#user_login' ).input ('您的账号' ) page.ele('#user_password' ).input ('您的密码' ) page.ele('@value=登 录' ).click()
采集猫眼电影榜 这个示例演示用浏览器采集数据 目标网址:https://www.maoyan.com/board/4
采集目标:排名、电影名称、演员、上映时间、分数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from DrissionPage import ChromiumPagefrom DataRecorder import Recorderpage = ChromiumPage() recorder = Recorder('data.csv' ) page.get('https://www.maoyan.com/board/4' ) while True : for mov in page.eles('t:dd' ): num = mov('t:i' ).text score = mov('.score' ).text title = mov('@data-act=boarditem-click' ).attr('title' ) star = mov('.star' ).text time = mov('.releasetime' ).text recorder.add_data((num, title, star, time, score)) btn = page('下一页' , timeout=2 ) if btn: btn.click() page.wait.load_start() else : break recorder.record()
下载星巴克产品图片 这个示例用于演示download()方法的功能 目标网址:https://www.starbucks.com.cn/menu/
采集目标:下载所有产品图片,并以产品名称命名
编码思路:按照页面规律,我们可以获取所有class属性为preview circle的元素,然后遍历它们,逐个获取图片路径,以及在后面一个元素中获取产品名称。再将其下载。并且这个网址页面结构非常简单,没有使用 js 生成的页面,可以直接使用 s 模式访问。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from DrissionPage import SessionPagefrom re import searchpage = SessionPage() page.get('https://www.starbucks.com.cn/menu/' ) divs = page.eles('.preview circle' ) for div in divs: name = div.next ().text img_url = div.attr('style' ) img_url = search(r'"(.*)"' , img_url).group(1 ) img_url = f'https://www.starbucks.com.cn{img_url} ' page.download(img_url, r'.\imgs' , rename=name)
 wechat
wechat alipay
alipay